BiLSTM-CRF:深入浅出理解序列标注的黄金搭档
BiLSTM-CRF:深入浅出理解序列标注的黄金搭档
前言
在自然语言处理(NLP)任务中,比如 命名实体识别(NER)、词性标注(POS tagging)、分块(Chunking) 等,我们面临的本质是一个 序列标注问题。如何高效捕捉前后文语义,并输出最优的标签序列?这时,BiLSTM + CRF 组合登场了。
这篇博客将用通俗易懂的方式讲清楚:$x_{n}$
什么是 BiLSTM?
什么是 CRF?
为什么它们要组合在一起?
用 PyTorch 实现 BiLSTM-CRF
一、序列标注简介
输入: 一个词语序列(如一个句子)
输出: 每个词对应一个标签(如人名/地名/组织/无)
例子:
1 | 输入: [李明, 在, 北京, 工作] |
传统机器学习方法如 HMM、最大熵、CRF 已用于此类任务多年。深度学习带来了 LSTM、BERT 等模型,对捕捉上下文能力有极大提升。但光靠 BiLSTM 输出每个词的预测,还不能保证整体标签序列的最优结构。这就是 CRF 发挥作用的地方。
二、什么是 BiLSTM?
LSTM 回顾
LSTM(长短期记忆网络)是一种特殊的 RNN,它解决了传统 RNN 在长序列学习中梯度消失的问题。
它通过门控机制记住长时间的上下文。
↔️ 双向 LSTM(BiLSTM)
在很多 NLP 任务中,一个词的含义依赖于它前后的词。BiLSTM 正是通过从前到后、从后到前两个方向分别编码信息,再拼接起来。
例如:处理“北京”这个词时,前向 LSTM 得知“在”,后向 LSTM 得知“工作”,有助于识别它是地名。
输出是每个词的一个向量表示,融合了前后文信息。
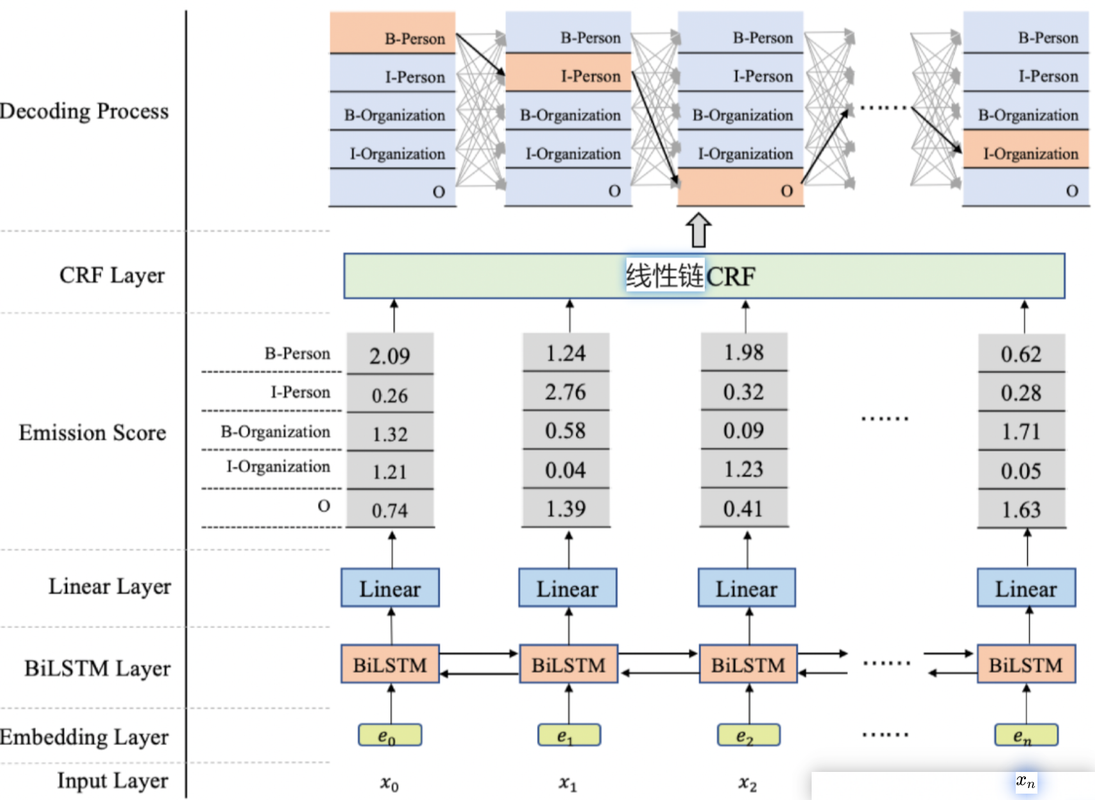
三、什么是 CRF?
CRF(条件随机场)是一个判别式的概率图模型,用于预测序列中的标签,考虑了标签之间的相互依赖。
BiLSTM 是对每个词独立预测标签;CRF 是找到全局最优的标签路径。
举个例子:
如果模型预测某个词是“B-LOC”,下一个词是“I-PER”,这在标注规范中是非法的。CRF 通过学习标签转移概率,避免这种情况。
公式上,我们最大化如下概率:
$$P(y | x) ∝ exp(∑ score(x_i, y_i) + ∑ transition(y_{i-1}, y_i))$$
即:
词与标签的匹配得分(由 BiLSTM 输出)
标签之间的转移得分(由 CRF学习)
最终通过 维特比算法(Viterbi) 找到全局得分最高的标签序列。
四、为什么 BiLSTM + CRF 是“绝配”?
| 模型 | 能力 |
|---|---|
| BiLSTM | 获取每个词的上下文语义信息 |
| CRF | 建模标签之间的依赖,输出最优序列 |
两者结合后的流程:
输入句子 -> 词向量
词向量喂入 BiLSTM -> 得到每个词的表示(contextual embeddings)
BiLSTM 输出 -> 作为 CRF 的发射得分
CRF 层解码标签序列(维特比)
效果远优于独立 softmax 分类的 LSTM。
五、PyTorch 实现简要示例
1 | import torch |
六、应用场景
命名实体识别(NER)
词性标注(POS Tagging)
拼写纠错(Grammatical Correction)
医疗、金融等垂直领域信息抽取
总结
| 模块 | 作用 |
|---|---|
| BiLSTM | 提取词的上下文特征 |
| FC层 | 生成每个标签的发射分数 |
| CRF | 找出最合理的标签序列 |
BiLSTM-CRF = 深度学习的表达能力 + 图模型的结构约束
在 NLP 序列标注任务中,仍然是经典而强大的模型组合。
 微信
微信 支付宝
支付宝




